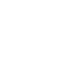【自有技术大讲堂】数据驱动的AI(系列10):以数据为中心的AI训练技巧
人工智能(AI)系统是由代码(实现学习的算法)和数据(用于训练系统)构建的。多年来,AI的通用方法是下载一些数据集并编写代码。这种开发模式对于今天的许多应用程序来说,AI系统的代码方面大多是一个已解决的问题。开发人员可以从GitHub下载一个满足项目需求的网络模型。不过在许多情况下,通过使用数据工程对数据集进行系统迭代,往往处理数据比花费时间在算法上效果更佳。
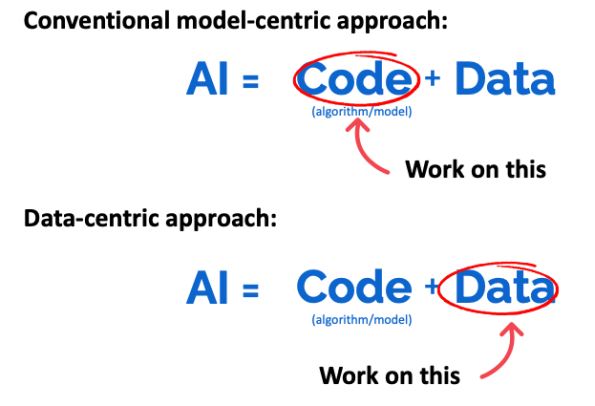
图1,传统模型驱动和数据驱动方式示意图
以数据为中心的AI是一种新兴技术方法。新方法的演变通常始于少数专家直观地执行这些技术。当这些专家讨论并发表他们的想法时,这些原则会变得更加广泛,最后开发了工具,使他们的应用更加系统化,并可供每个人使用。就以数据为中心的AI而言,越来越多的人有了应用系统化数据处理方法的心态。
接下来将分享五大数据中心AI开发技巧,以及数据标注示例,以便用户应用这些原则。
技巧1:使标签保持一致
如果存在从输入x到输出y的某种确定性(即非随机)函数映射,并且标签与该函数一致,则学习算法学习任务要容易得多。如果能设计一个这样的数据集,通常可以在更小的数据集上以更高的精度工作。比如检测物体的划痕,然后通过目视检查对缺陷进行标记,如下图所示:

图2,正负样本的分布统计示意图
技巧2:使用多个标注人员来发现不一致之处
如果怀疑标注人员在标注数据的方式上不一致,请两个标注人员标注同一示例是很有帮助的。如果第一个标注人员将缺陷标注为缺口,而第二个标注人员则将其标注为划痕,那么就知道数据集中至少存在一个不一致。其他常见的不一致性包括边界框大小、边界框数量、标签名称等。如果能够识别不一致性并将其清除,算法的性能就能显著提高。
技巧3:通过追踪不明确的标签进行反复清洗
当试图简化数据标记过程时,识别不明确的标注可以帮助明确如何标注。重要的是,需要积极寻找模棱两可或不一致的标签,然后在文档中提供明确的标签决定。记住:有决定总比没有决定好。正确创建此标签说明文档后,可显著提高标签质量。
技巧4:扔掉坏例子,数据越多越好!
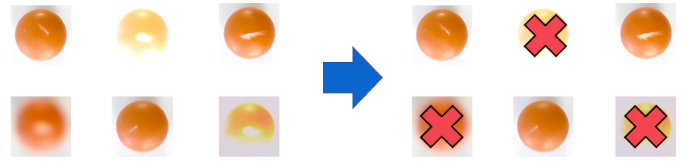
图3,清洗剔除错误标注示意
如上图所示,如果要求训练学习算法来检测物体上的缺陷,可能只会混淆学习算法,因为数据质量太差了。相反,如果发现一些图像聚焦不好或对比度差,就应该舍弃它们。即使这样只剩下一半的训练集,你的算法也能更清楚地检测你正在寻找的缺陷。
在许多应用中,改进成像系统设计也是至关重要的。在这个例子中,我会回到设计成像系统的人那里,礼貌地要求重新聚焦相机并调整照明或对比度。就会发现这样会得到更好的结果。有时,成功应用程序的途径不是通过获取坏数据并对其进行处理;修复图像采集以获得更好的图像并使算法更容易解决问题,也可能更有效。
技巧5:使用错误分析来关注要改进的数据子集
通常,得到一个数据集时,数据的很多不同方面都需要工作,无论是清理标签、设置阈值、捕获更好的数据等等。试图同时改善数据的所有这些不同方面都可能是一项过于广泛和无重点的工作。相反,重复使用错误分析对于决定学习算法性能是至关重要的。
例如,如果认为在划痕上的性能不够好,这就需要将注意力集中在有划痕的图像子集上,不断的去优化这个子类标签,做到有的放矢。
总结
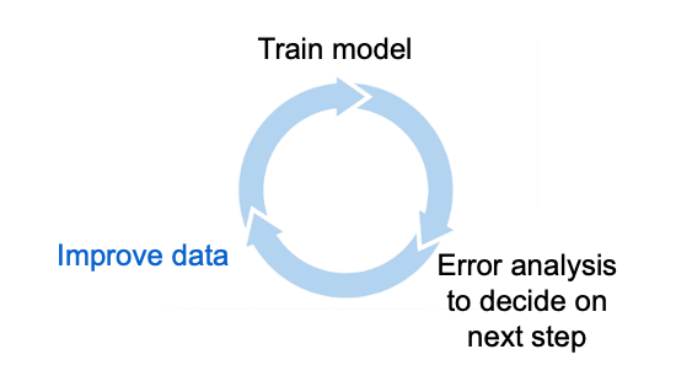
图4,模型优化循环示意图
关于以数据为中心的AI的一个常见误解是,这一切都与数据预处理有关。它实际上是关于开发深度学习CV系统的迭代工作流程,需要不断的清洗数据。改进AI系统的最有效方法之一是对数据进行工程设计,以解决错误分析中发现的问题,然后再次尝试训练模型。