【自有技术大讲堂】数据驱动的AI(系列6):使用cleanlab挑选错误标签
CleanLab利用机器学习算法自动查找分析真实世界数据集中错误的数据标签;评估数据集质量;基于噪声数据训练相对可靠的模型。简单来说,CleanLab为数据标签有关的机器学习任务提供了更高效的框架。
机器学习任务80%的工作量在数据准备,这是公认的消耗时间又无趣的任务。数据的质量直接影响模型的性能,数据集的错误标签可能会误导数据科学家选择较差的实际部署模型;与此同时,研究复杂模型比人工检查手动清理一张张数据更具有吸引力,但往往后者会得到更好的结果。CleanLab通过自动标记,让数据科学家仅仅需要关注少量可疑数据,能够很大程度上减轻数据准备工作的痛苦。
CleanLab主要功能:
1、在数据集中查找相关问题并按数据点的质量进行排名;
2、改善任何有数据集标签问题的分类模型;
3、查找并合并/删除数据集内出现重叠的数据;
值得注意的是,以上功能仅需要极少量的代码即可实现。
下面展示CleanLab在MNIST数据集中找到的错误标签:

图1 CleanLab在MINIST数据集中的应用
如图1中1行3列所示,MINIST数据集中原原始标签为5,但是经过CleanLab计算,给出了标签为3的估计,且置信度达到了100%,显然3才是真实的标签。
通过CleanLab在各大开源数据集上的测试得到以下结果:
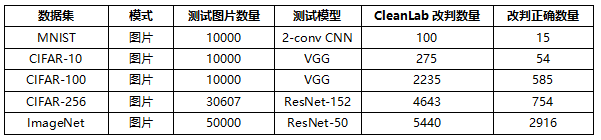
图2 开源数据集中的错误标签
通过图2可以看到,错误标签普遍存在于开源数据中,CleanLab在查找错误标签时的作用也是明显的。
34个不同的基准模型分别在原始开源数据测试集以及经过校对的测试集进行实验得到以下结果:
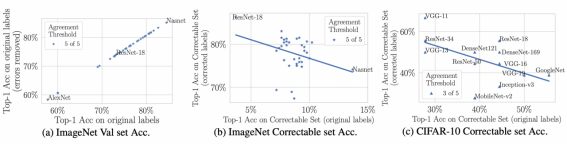
图3 错误的测试数据对BenchMark的影响
由图3(a)可以看到,剔除错误标签对BenchMark基本没有影响;但在校对测试集上BenchMark发生较大改变,值得注意的是在ImageNet数据集上Nasnet在校对数据集上的表现由1/34变为34/34,而ResNet18则变成了1/34。详情可参考原文https://arxiv.org/abs/2103.14749
CleanLab通过置信度学习,自动筛选可疑样本,大幅减轻了数据工作者的工作量,最后附上开源连接:https://github.com/CleanLab/CleanLab,让我们都使用起来吧!